

Let us imagine a tree made up of if-else situation having different conditions in each node such that all the nodes cover up different conditions and the decision of classification comes at the leaf node of the tree. In this way, decision trees are prepared which makes the decision of a sample based on its features.
Significance of decision trees:
Versatile nature — They can perform both classification as well as regression and also multioutput tasks like SVMs.
Powerful algorithms, capable of fitting complex datasets
Easy visualization
Robust to outliers
Automatic Feature Selection
Train a Decision Tree
Training a decision tree involves constructing the tree by recursively partitioning the data based on features. The process aims to create a tree that makes decisions at each node, leading to leaf nodes that represent the predicted outcomes.
Load the dataset
Split the data into training and testing sets
Create a decision tree classifier
Set the parameters of decision tree if needed
Train the decision tree on the training data
How decision tree performs training
Start with the Entire Dataset: The root of the tree includes all the training examples.
Select a Feature to Split On: Choose a feature that best separates the data into distinct classes or reduces impurity
Determine the Splitting Criterion: Decide on a condition for the selected feature to split the data into subsets.
Create Child Nodes: Create child nodes for each subset created by the split.
Repeat the Process: Recursively repeat the process for each child node, selecting features and creating splits until a stopping condition is met.
Stopping Conditions: Define stopping conditions to halt the tree-building process.
Assign Labels to Leaf Nodes: Once a stopping condition is met, assign a class label to each leaf node based on the majority class of the samples in that node.
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X_train, y_train)
Visualize the Decision Tree
It is easy to visualize the decision tree with the help of export_graphvis() method to output a graphical representation file called as dot file.
The export_graphviz function in scikit-learn is a tool that allows to export a decision tree in a format that can be visualized using Graphviz. Graphviz is an open-source graph visualization software that represents structural information as diagrams of abstract graphs and networks.
from sklearn.tree import export_graphviz
import graphviz
export_graphviz(tree_clf, out_file="iris_tree.dot", feature_names=iris.feature_names[2:], class_names=iris.target_names, rounded=True, filled=True)
with open("iris_tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
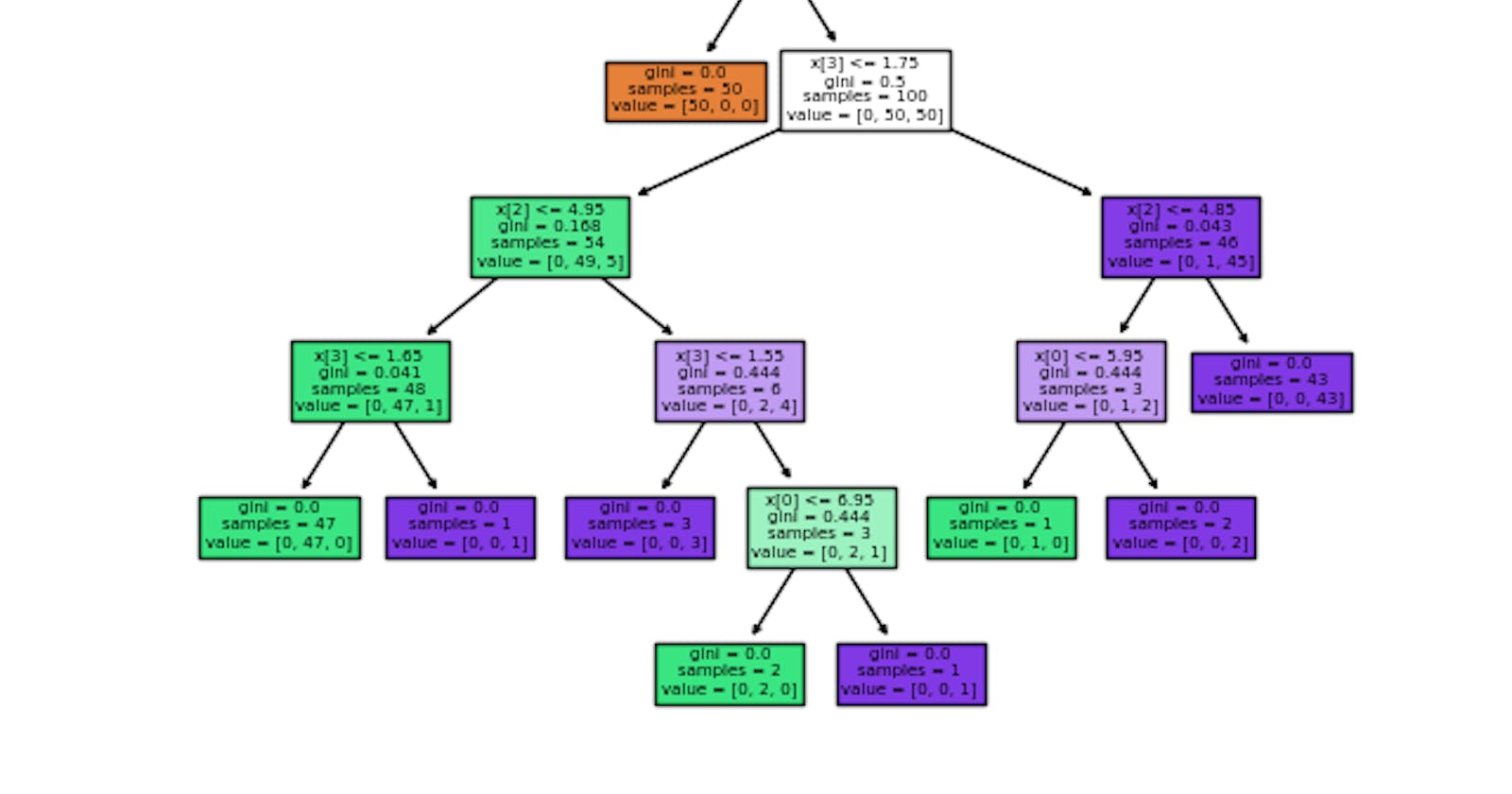
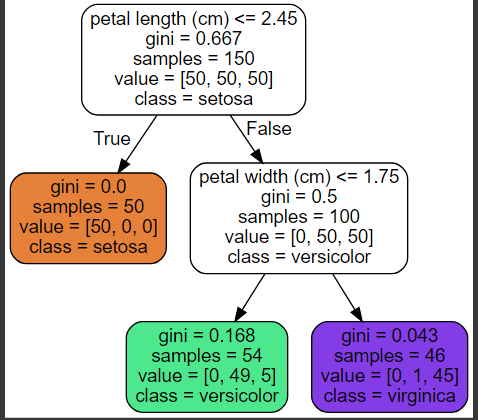
Below shown is the visualization of decision tree made up of different conditions. The first condition shows for Setosa class and then in second layer, it shows condition for versicolor while at third layer if none of two conditions get satisfied, the sample will be virginica. As said earlier, all the samples are present at the leaf nodes of the decision tree.
Making Predictions
The process of classification starts from the root node and it checks for the first condition. If condition gets satisfied, the node moves to left side towards true condition and it leaves to leaf node satisfying properties of one of the classes of the samples. The second condition checks for another target for the samples provided and it keeps on moving to lower leaf nodes such that it will give the result of the target to which the sample belongs at the leaf node of the decision tree.
y_pred = tree_clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
This will predict the target class to which the test samples belong to and the accuracy can be checked by accuracy_score metric. One of the many qualities of the decision trees is that they require very little data preparation. In particular, they don’t require feature scaling or centering at all.
A node’s samples attribute counts how many training instances it applies to. A node’s value attribute tells how many training instances of each class this node applies to. A node’s gini attribute measures its impurity: a node is “pure” (gini=0) if all training instances it applies to belong to the same class.
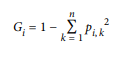
Here Gi gives the Gini impurity where p(i, k) is the ratio of class k instances among the training instances in the ith node.
Methods
apply(X[, check_input])
Return the index of the leaf that each sample is predicted as.
cost_complexity_pruning_path(X, y[, ...])
Compute the pruning path during Minimal Cost-Complexity Pruning.
decision_path(X[, check_input])
Return the decision path in the tree.
fit(X, y[, sample_weight, check_input])
Build a decision tree classifier from the training set (X, y).
Return the depth of the decision tree.
Get metadata routing of this object.
Return the number of leaves of the decision tree.
get_params([deep])
Get parameters for this estimator.
predict(X[, check_input])
Predict class or regression value for X.
Predict class log-probabilities of the input samples X.
predict_proba(X[, check_input])
Predict class probabilities of the input samples X.
score(X, y[, sample_weight])
Return the mean accuracy on the given test data and labels.
set_fit_request(*[, check_input, sample_weight])
Request metadata passed to the fit method.
set_params(**params)
Set the parameters of this estimator.
set_predict_proba_request(*[, check_input])
Request metadata passed to the predict_proba method.
set_predict_request(*[, check_input])
Request metadata passed to the predict method.
set_score_request(*[, sample_weight])
Request metadata passed to the score method.
Hope you have liked this article having an understanding of decision tree.
Thank you!